%22%3E%3Cpath%20d=%22M63.318%20472.594c-19.675-.352-60.526%2022.702-63.24-23.015-2.14-36.036%2038.685-24.437%2063.044-29.552%2016.7-3.509%2045.587-10.294%2046.37-17.927%203.823-37.601%2030.1-78.583-6.276-113.497-19.244-18.475-41.934-33.583-59.69-53.258-6.224-6.889-5.363-23.981-1.697-34.249%201.592-4.462%2018.41-3.732%2028.378-4.775%202.322-.248%205.075%201.644%207.32%203.04%2022.401%2014.051%2051.118%2044.738%2065.809%2039.037%2035.593-13.778%2065.562-43.369%2095.544-69.229%206.341-5.466%205.963-22.871%203.38-33.492-3.053-12.564-14.183-23.119-17.353-35.684-2.179-8.624%201.996-19.78%206.223-28.377.927-1.892%2016.192-.183%2021.32%204.097%2016.335%2013.62%2029.095%2032.422%2046.917%2043.068%2014.222%208.468%2035.019%2012.956%2050.545%209.29%207.88-1.866%2012.851-25.286%2015.056-39.598%202.818-18.305-.496-37.641%202.949-55.75%201.526-8.012%2013.608-19.976%2020.145-19.52%207.711.536%2018.344%2011.417%2021.045%2019.924%204.736%2014.965%205.988%2031.56%205.897%2047.465-.209%2038.02%2016.557%2057.303%2054.85%2065.732%2035.084%207.711%2060.448%208.402%2077.853-29.526%209.759-21.28%2026.642-39.898%2042.99-57.186%205.441-5.753%2021.541-7.854%2028.417-3.966%206.38%203.614%2012.056%2019.623%209.185%2026.434-11.351%2026.864-27.542%2051.653-39.115%2078.439-5.532%2012.799-11.534%2033.127-5.493%2041.699%2016.309%2023.093%2031.979%201.879%2046.448-7.802%2022.167-14.809%2043.447-30.987%2066.175-44.804%205.362-3.275%2019.688-2.101%2021.711%201.552%204.357%207.881%207.854%2021.633%203.796%2027.778-11.573%2017.548-26.264%2033.335-41.32%2048.196-14.978%2014.809-44.008%2026.421-45.548%2041.594-3.679%2036.193%204.084%2073.86%2010.412%20110.379.822%204.723%2020.81%209.616%2031.287%208.507%2031.718-3.34%2063.018-11.573%2094.749-13.556%209.654-.6%2027.32%2011.86%2028.455%2020.119%201.318%209.537-9.902%2028.43-18.579%2030.387-35.984%208.115-73.051%2015.004-109.739%2015.095-22.598.066-39.246%203.236-39.312%2025.521-.026%2010.242%2015.226%2024.411%2026.812%2029.995%2022.154%2010.633%2065.745%203.653%2056.703%2040.068-9.798%2039.507-48.861%2017.483-75.869%2013.634-24.881-3.549-46.2-4.54-65.066%2017.731-19.349%2022.859-22.676%2040.094%204.044%2058.83%2017.431%2012.225%2035.15%2025.272%2048.653%2041.372%206.667%207.946%209.512%2028.013%204.175%2034.732-5.923%207.45-26.485%2011.86-34.809%207.176-25.273-14.195-49.345-31.626-70.729-51.236-17.614-16.153-32.631-23.407-56.664-13.791-27.882%2011.168-23.289%2031.665-21.306%2053.037%202.205%2023.693%205.649%2047.53%204.684%2071.146-.287%206.967-13.23%2018.083-21.162%2018.801-8.025.743-20.811-7.085-24.686-14.652-5.78-11.26-4.592-25.873-8.154-38.568-7.502-26.707%2015.826-67.101-37.354-73.625-47.975-5.884-49.801%2027.712-58.908%2057.838-3.014%209.994-6.55%2020.628-12.93%2028.495-4.032%204.971-14.404%208.324-20.706%206.915-6.093-1.357-15.148-9.811-15.056-15.017.352-21.045%204.827-42.012%205.61-63.096.548-14.678%202.596-33.323-5.036-43.356-12.499-16.465-31.392-35.801-49.332-37.745-12.825-1.383-28.808%2023.406-42.82%2037.119-9.499%209.316-16.622%2021.763-27.425%2028.782-7.568%204.919-25.234%207.424-28.365%203.34-6.798-8.885-12.734-24.972-9.016-34.001%207.972-19.375%2020.798-37.367%2034.341-53.689%2020.079-24.189%2033.935-46.109%2012.225-78.035-20.406-30.048-18.279-31.483-80.762-24.79zm514.476-102.707c-.17-64.244-16.883-96.04-57.904-133.773-71.002-65.34-220.98-43.564-281.114%203.132-59.508%2046.226-75.034%20131.006-43.33%20211.494%2037.067%2094.149%20112.063%20151.282%20190.111%20144.693%207.945-.678%2015.865-2.087%2023.68-3.731%20104.325-22.024%20168.857-107.013%20168.557-221.815z%22%20fill=%22%23000%22/%3E%3C/g%3E%3Cdefs%3E%3CclipPath%20id=%22a%22%3E%3Cpath%20fill=%22%23fff%22%20d=%22M0%200h8e2v8e2H0z%22/%3E%3C/clipPath%3E%3C/defs%3E%3C/svg%3E)
Типизация в Python (ru)
11-02-2026
В этой статье рассматриваются два ключевых вопроса. Зачем использовать типизацию в языке Python, который позволяет писать без неё? И как писать типизированный код на Python правильно? Постараемся быстро познакомиться со всеми необходимыми инструментами, чтобы после прочтения вы уже могли начать осознанно писать свои программы типизированными, ведь это совсем не сложно!
# Динамика vs Статика
Итак, что же такое типизация? Новым это понятие может оказаться только для питонистов, ведь большинство классических языков таких как C, Java, Rust и многие другие исходно были созданы, как языки со статической типизацией. Но что это означает? Давайте рассмотрим небольшой пример на C:
int sum(int a, int b) {
return a + b;
}
int main() {
printf("%d\n", sum(10, 20));
// printf("%d\n", sum("10", 20));
}
Такой код работает и выводит число 30. Но обратите внимание,
что последняя строка закомментирована. Если мы раскомментируем
её и опять попробуем скомпилировать программу, то получим
примерно вот такой лог ошибки:
error: passing argument 1 of ‘sum’ makes integer from pointer without cast
10 | printf("%d\n", sum("10", 20));
| ^~~~
| |
| char *
note: expected ‘int’ but argument is of type ‘char *’
Лог сообщает нам, что параметр функции, ожидая int, получил
аргумент типа char * (для упрощения можем считать это
эквивалентом строки). На первый взгляд ничего удивительного, для
нас с вами — питонистов, в этом нет. Ведь вот такой код на Python
тоже упал бы с ошибкой:
def sum(a, b):
return a + b
print(sum("10", 20)) # TypeError
В чем же разница, спросите вы? Давайте немного подправим оба этих
примера на C и на Python. Попробуем вызвать функцию sum от двух
строк:
print(sum("10", "20")) # > 1020
Здесь мы не получаем никаких ошибок, потому что действует полиморфизм, а для строк операция сложения тоже реализована. Но что будет в C?
int main() {
printf("%d\n", sum("10", "20"));
}
Такую программу не выйдет даже скомпилировать. Мы опять получим
точно такой же лог ошибки, который был ранее. Обратите внимание
на то, как мы определяли функцию sum в языке C. Там мы явно
указали типы входных аргументов как int. Это означает, что
аргумент любого другого типа нельзя передать в эту функцию. Это
и называется статической типизацией. Также статическая типизация
обязывает указать тип для каждой переменной и запрещает менять
типы переменных после определения оных. То есть тип фиксирован,
статичен.
Вторая же группа языков называется динамически типизированными. Это такие языки как Python, Lua, JavaScript и другие. В них, соответственно, тип переменной строго не фиксирован и может меняться в ходе исполнения программы.
# Преимущества типизации
Пора перейти к вопросу, зачем типизация нам нужна, если в том же Python всё и так работает отлично. Во-первых, это скорость. На низком уровне (чем бы он ни был представлен) нам в любом случае нужно знать типы переменных. А тот факт, что мы можем позволить себе, их не выставлять, лишь означает, что кто-то делает это за нас (например, виртуальная машина), а это в свою очередь требует ресурсов. Отсюда и картина, которую мы наблюдаем в рейтингах языков по скорости:
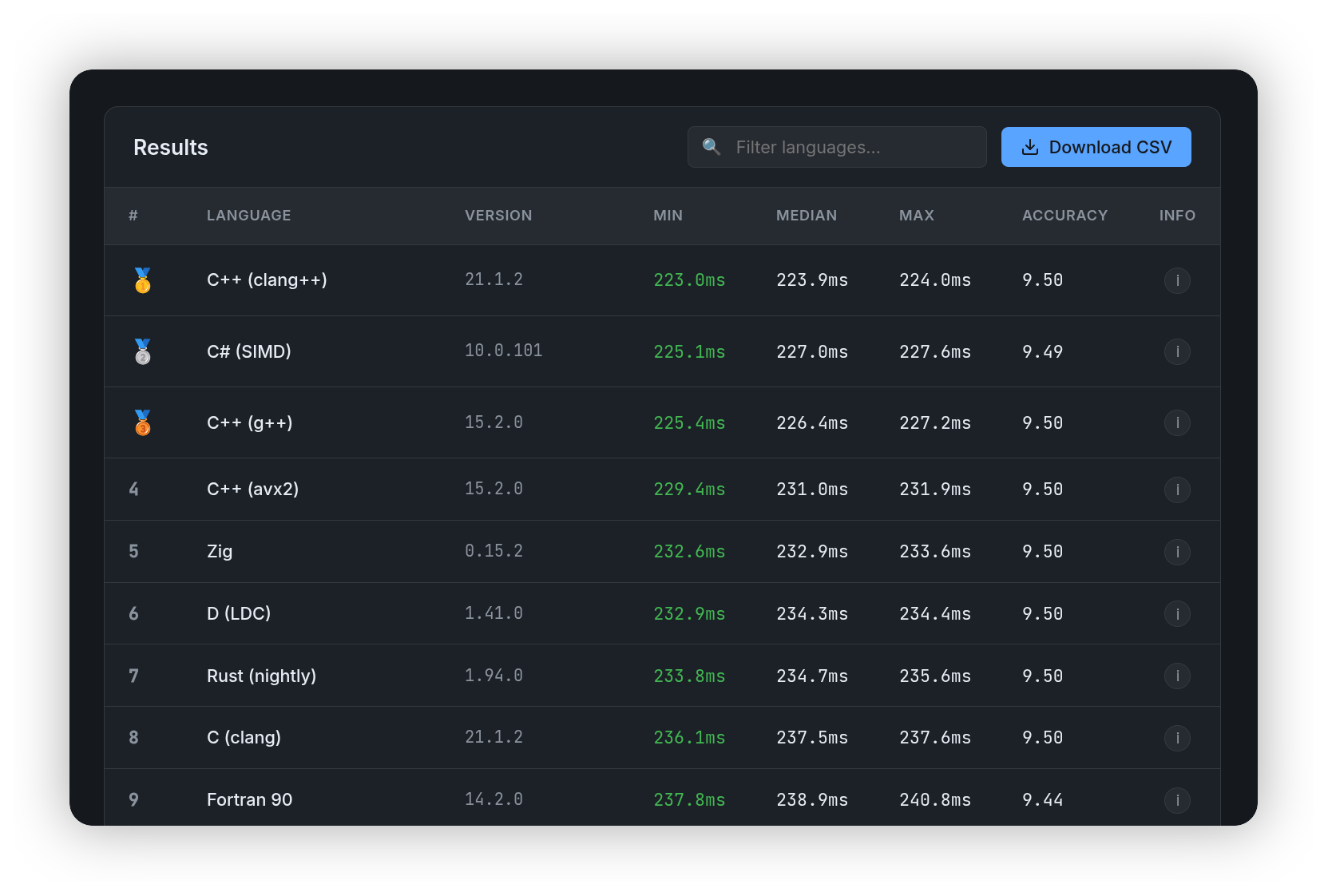
Python в этом рейтинге, кстати говоря, на последнем месте. Может быть типизированный Python как раз поможет нам исправить этот печальный факт? К сожалению, нет. Поскольку Python как не был исконно, так по сей день остается, не статически типизированным языком. Аннотации типов в Python остаются опциональными, их можно не указывать. И сам интерпретатор Python в runtime не проверят их.
Тут мы переходим ко второму преимуществу, которое открывают для нас типы. И это качество кода.
«Цель типизации в Python — помочь инструментам разработки искать ошибки в кодовых базах на Python с помощью статического анализа, то есть не выполняя тестов кода.»
Лусиану Рамальо, «Python. К вершинам мастерства»
Расширяя эту мысль, мы можем уточнить, что цели типизации это:
- Раннее выявление ошибок — до runtime-а, до падения кода на продакшене
- “Экстракция” тестов — правильная типизация помогает уменьшить количество тестов, писать и поддерживать которые сложнее, чем типы. В тестах остаётся тестировать бизнес логику, а не банальное несоответствие примитивов.
- Улучшение читаемости кода — PEP 20 говорит нам о том, что “явное лучше неявного”. Когда мы читаем код, нам достаточно увидеть сигнатуру функции, не вчитываясь в её реализацию
- Упрощение разработки в IDE — больше подсказок и предупреждений о потенциальных ошибках.
- Повышение качества архитектуры — типы “заставляют” проектировать правильные абстракции.
# Как писать типизированно
Перед тем, как переходить к коду, давайте разберёмся с тремя важными понятиями: интерфейс, абстрактный класс и протокол. В чем разница? Давайте по порядку:
- Интерфейс — это класс, у которого все методы абстрактные, то есть не содержат деталей реализации.
- Абстрактный класс — это класс, у которого, помимо абстрактных методов, есть еще и реализованные методы.
- Протокол — это неявный интерфейс.
Первые два понятия должны быть понятны. А на последнем давайте остановимся. В Python реализация паттерна интерфейса работает через наследование, то есть, класс, реализующий интерфейс, наследуется от этого класса-интерфейса. При этом класс, который реализует протокол, не наследуется от него и вообще может о нем не знать.
## Примитивы
Давайте наконец посмотрим на то, как же писать типизированный код. Начнем с простейшего примера функции, которая мультиплицирует переданную ей строку $n$ раз.
def multi_string(string, n):
return string * n
print(multi_string("cat", 3)) # > catcatcat
Это простейшая функция, которая принимает на вход строку и число, а возвращает строку, полученную путём конкатенации исходной строки с самой собой $n$ раз. Давайте типизируем эту функцию!
def multi_string(string: str, n: int) -> str:
return string * n
Синтаксис простой: типы для входных параметров мы подписываем через двоеточие, а выходной тип с помощью стрелочки. Теперь наши редакторы кода (IDE) будут подсвечивать для нас ошибку, в случае если мы неправильно передадим входные или неправильно обработаем выходные значения функции:
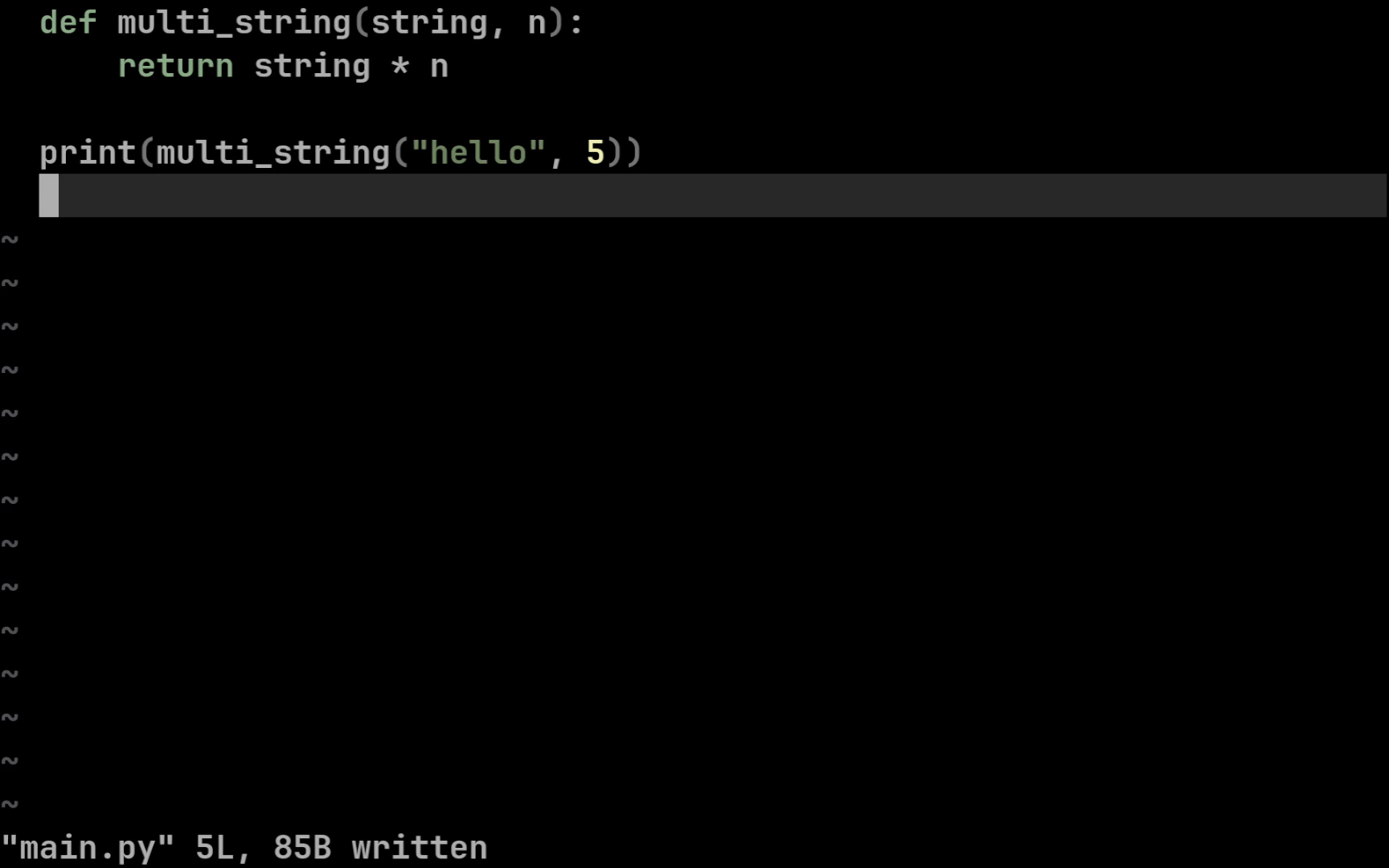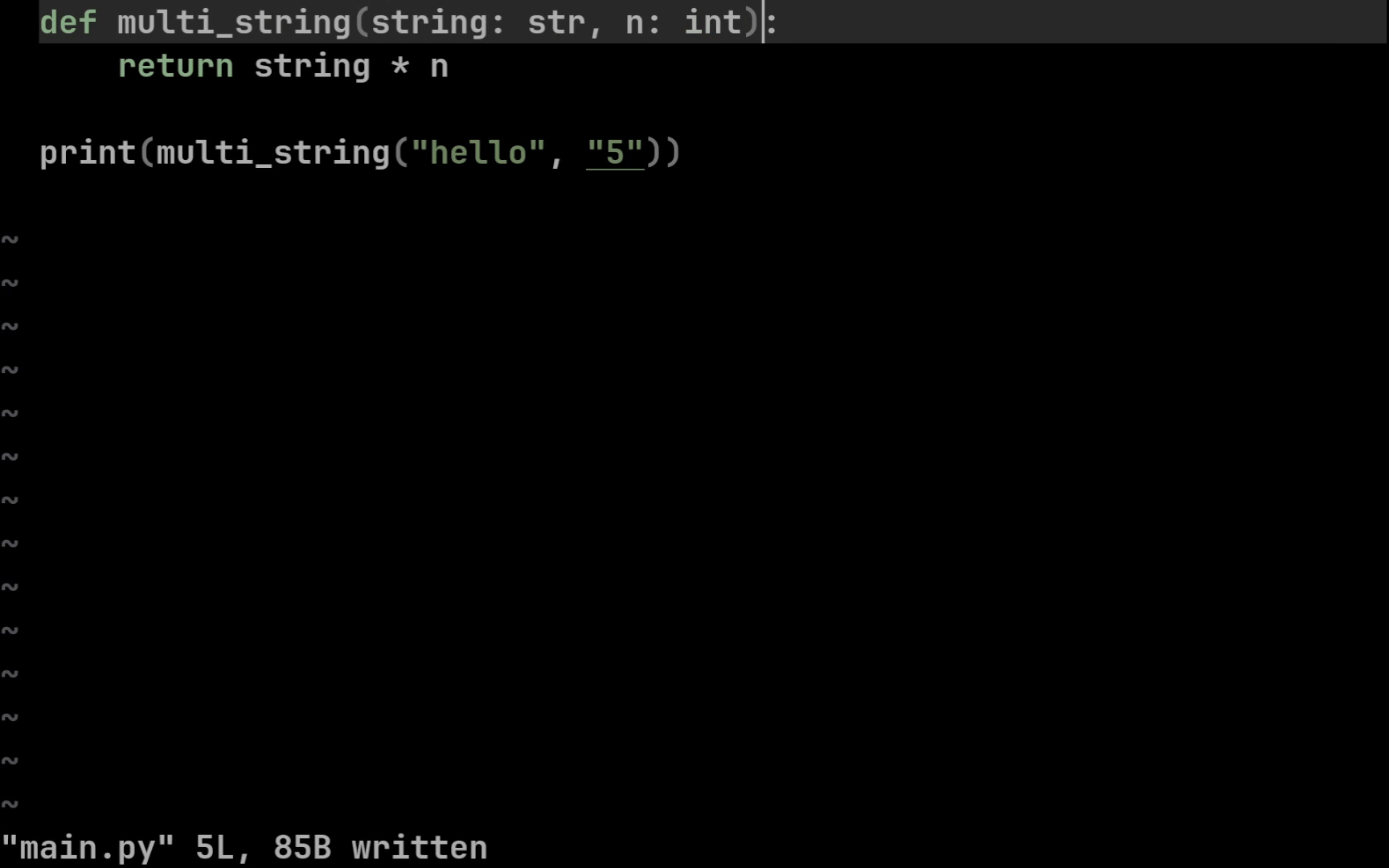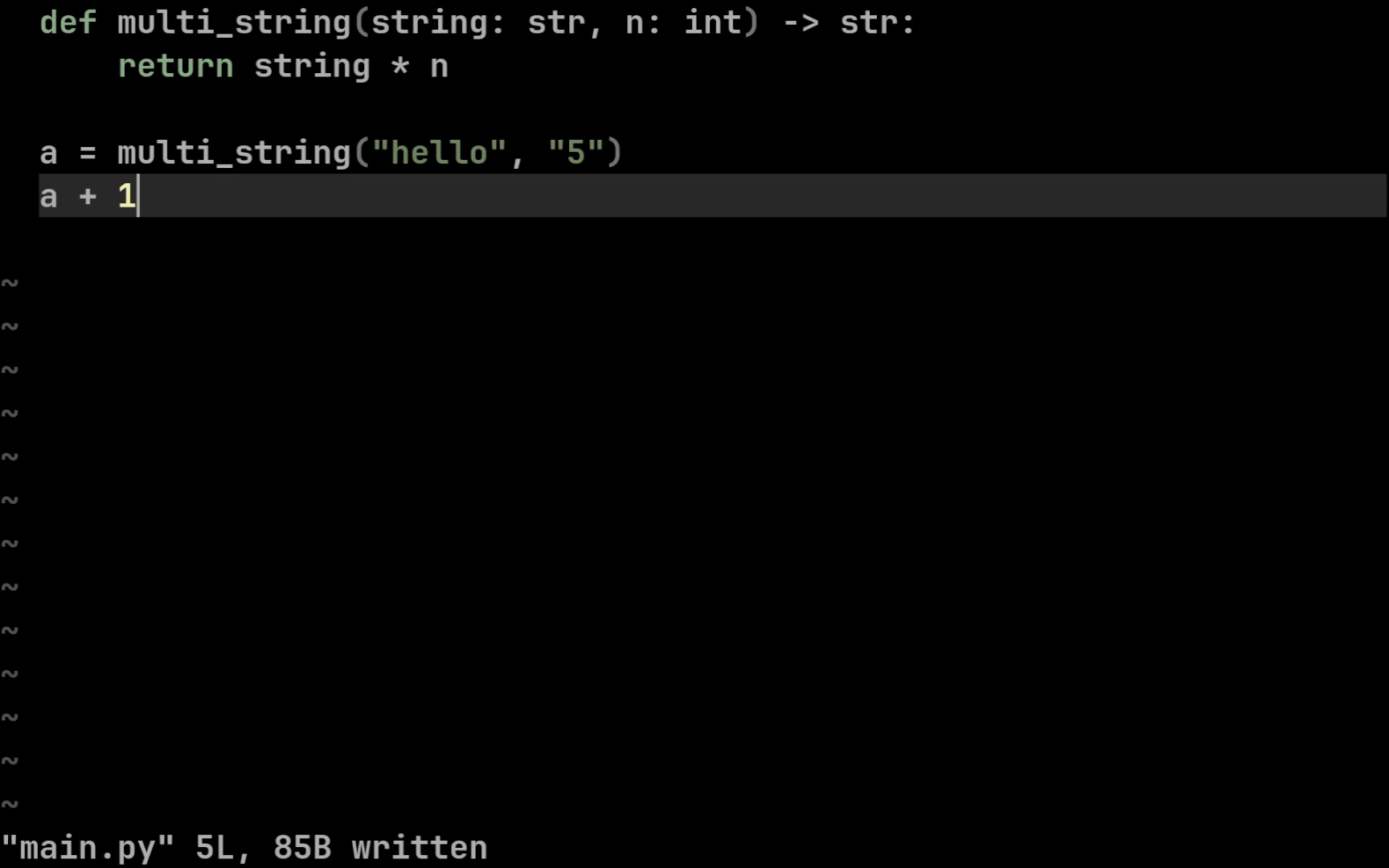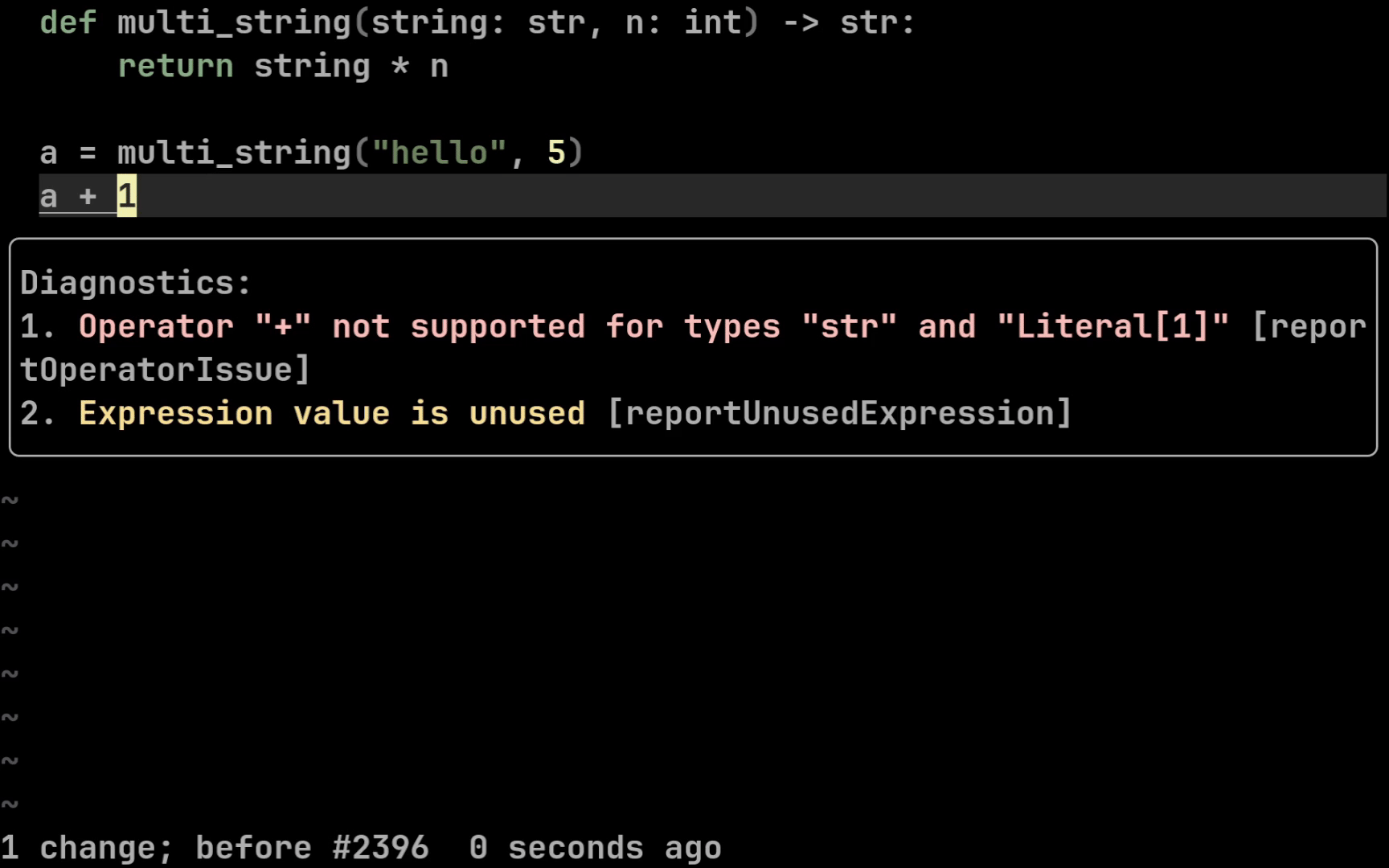
Таким образом можно проаннотировать все классические примитивы
— str, int, bytes, float, Decimal, bool.
## Объединение типов
В реальности, конечно, бывают и более сложные кейсы, когда функция может принимать и работать с разными типами, но все же не любыми. В таких случаях можно использовать объединение типов:
def normalize(data: str | bytes) -> str:
if isinstance(data, bytes):
return data.decode("utf-8")
return data
В примере выше функция normalize принимает на вход либо строку,
либо последовательность байт и на выход всегда возвращает строку
в кодировке utf-8. Через union (|) можно перечислить любое
количество типов, но важно понимать, где это уместно. Если вам
хочется написать простыню из объединения десяти типов, стоит
хорошенько подумать. О том как такие ситуации разрешаются, мы
скажем ниже.
Объединение также можно использовать и в указании типа возвращаемого значения. Но использовать это стоит только для спецификации опциональности. Например:
def parse_int(value: str) -> int | None:
if not value.isdigit():
return None
return int(value)
По сути, тут мы говорим, что результат функции опционален. Она
может вернуть int, либо не вернуть его, если что-то пошло не
так. Однако, аннотировать возвращаемое значение как int | str
или любым другим подобным образом, где мы просто объединяем два
совершенно разных типа, считается плохой практикой. Потому что
в таком случае непонятно, как обрабатывать результат этой
функции. В результате функции мы можем ожидать либо конкретную
реализацию, про которую нам точно известны её методы и атрибуты,
либо None. Отступление от этого, как правило, будет приводить
к усложнению кода.
## Спецификация коллекций
Помимо примитивов мы конечно же можем аннотировать и коллекции.
Но лучше не ограничиваться простым data: list, а специфицировать
и содержание коллекции тоже. Это можно сделать, используя
синтаксис квадратных скобок. Давайте приведём несколько примеров:
def format_user(user: tuple[str, int]) -> str:
name, score = user
return f"{name}: {score} points"
def average(values: list[float]) -> float:
if len(values) == 0:
return 0
return sum(values) / len(values)
def total_count(counters: dict[str, int]) -> int:
return sum(counters.values())
Это, конечно, не покрывает все возможные сценарии, которые могут возникнуть в реальном продакшн коде. В секциях TypedDict, NamedTuple, Dataclass мы расширим наш инструментарий.
## Mapping и MutableMapping
Mapping и MutableMapping — это абстрактные классы для
словари-подобных структур. Mapping гарантирует только чтение
(ключи, значения, итерацию), а MutableMapping говорит, что
объект можно изменять.
from collections.abc import Mapping, MutableMapping
def read_config(cfg: Mapping[str, str]) -> str:
return cfg["DATABASE_URL"]
def patch_config(cfg: MutableMapping[str, str]) -> None:
cfg["DEBUG"] = "1"
Если функция только читает данные, указывайте Mapping. Если
меняет — MutableMapping. Это маленькая, но важная подсказка для
читателя и статического анализатора.
## NamedTuple
Когда нужно описать структуру с фиксированным набором полей и
одновременно сохранить поведение кортежа, удобно использовать
NamedTuple. Это неизменяемый тип данных, который можно
индексировать и при этом читать поля по именам.
from typing import NamedTuple
class User(NamedTuple):
id: int
username: str
score: int
def print_user(user: User) -> str:
return f"{user.username} ({user.id}) = {user.score}"
NamedTuple хорошо подходит для компактных структур данных,
которые не должны изменяться после создания. Если вам нужны
изменяемые поля и более богатое поведение, лучше выбрать
dataclass или обычный класс.
## TypedDict
Если же ваша структура — это обычный словарь, но вы хотите
типизировать ожидаемые ключи и значения, используйте TypedDict.
Такой тип описывает форму словаря и работает только на уровне
статического анализа.
from typing import TypedDict
class User(TypedDict):
id: int
username: str
email: str | None
def send_email(user: User) -> None:
...
Это особенно полезно, когда данные приходят из JSON или другого динамического источника, но вы хотите строгий контракт по ключам. Если часть ключей опциональна, опишите их явно, чтобы не терять проверку на уровне типов.
## Dataclass
dataclass — это удобный способ описать “контейнер данных” с
инициализатором, сравнениями и читаемым repr. Такой класс
изменяем, если не указать обратное, и отлично подходит для домена
или DTO.
from dataclasses import dataclass
@dataclass
class User:
id: int
username: str
email: str | None = None
def normalize(user: User) -> User:
user.username = user.username.lower()
return user
dataclass хорош, когда нужна структура, которая может
изменяться, и когда важна ясная модель данных. Если объект
должен быть неизменяемым, используйте @dataclass(frozen=True).
## Enum
Enum помогает описать закрытый набор значений. Это полезно,
когда у поля есть строго ограниченный набор допустимых вариантов,
и вы хотите, чтобы типы не позволяли случайные строки.
from enum import Enum
class Status(Enum):
NEW = "new"
DONE = "done"
FAILED = "failed"
def is_done(status: Status) -> bool:
return status is Status.DONE
Такой подход удобен для статусов, ролей, флагов, режимов работы, то есть любого “перечислимого” доменного значения.
## Кастомные классы
Конечно же система типов позволяет специфицировать не только примитивы, но и наши собственные или библиотечные классы. Например:
class User:
id: int
username: str
email: str
friends: list[User]
def hand_shake(user1: User, user2: User) -> None:
user1.friends.append(user2)
user2.friends.append(user1)
## Абстрактные классы
В Python у нас существует прекрасный модуль collections.abc. Там
уже описан ряд абстрактных классов, которые в 90% случаев закроют
все наши потребности. Они полезны, когда вы хотите описывать
поведение, а не конкретную реализацию. Итак, что же там
представлено? А вот что:
collections.abc.ABCMeta
collections.abc.AsyncGenerator
collections.abc.AsyncIterable
collections.abc.AsyncIterator
collections.abc.Awaitable
collections.abc.Buffer
collections.abc.ByteString
collections.abc.Callable
collections.abc.Collection
collections.abc.Container
collections.abc.Coroutine
collections.abc.EllipsisType
collections.abc.FunctionType
collections.abc.Generator
collections.abc.GenericAlias
collections.abc.Hashable
collections.abc.ItemsView
collections.abc.Iterable
collections.abc.Iterator
collections.abc.KeysView
collections.abc.Mapping
collections.abc.MappingView
collections.abc.MutableMapping
collections.abc.MutableSequence
collections.abc.MutableSet
collections.abc.Reversible
collections.abc.Sequence
collections.abc.Set
collections.abc.Sized
collections.abc.ValuesView
Как мы видим тут большое количество абстрактных классов. Большинство из них созданы для описания какого-то свойства коллекции. Аннотируя с их помощью код, мы можем выражать более широкие полиморфные границы наших функций. Например:
from collections.abc import Iterable
def total(values: Iterable[int]) -> int:
return sum(values)
total([1, 2, 3])
total((1, 2, 3))
total({1, 2, 3})
Иногда можно встретить такие же импорты из модуля typing:
from typing import Iterable, Sequence. Но в реальности это
просто реэкспорт реализаций из collections.abc. Поэтому сейчас
лучше импортировать абстрактные классы напрямую из
collections.abc.
## Sequence и Iterable
Эти два типа часто путают. Iterable гарантирует только то, что
объект можно перебирать в цикле. Никаких индексов, длины или
упорядоченности тут не обещается. Sequence же, кроме
возможности итерации, гарантирует наличие индексации и длины,
то есть __getitem__ и __len__. Из этого вытекает разница
в том, что можно безопасно делать с объектом.
from collections.abc import Iterable, Sequence
def sum_any(values: Iterable[int]) -> int:
total = 0
for v in values:
total += v
return total
def head(values: Sequence[int]) -> int:
return values[0]
Функция sum_any примет и список, и кортеж, и генератор.
Функция head уже не сможет принять генератор, потому что у него
нет индексации, и мы не можем написать values[0]. Поэтому,
когда вам важно только итерироваться — используйте Iterable,
а если вы опираетесь на индексацию или длину — Sequence.
## Callable
Callable используется, когда функция принимает другую функцию.
Это особенно важно для коллбеков, обработчиков событий и функций
высшего порядка.
from collections.abc import Callable
def apply(values: list[int], fn: Callable[[int], int]) -> list[int]:
return [fn(v) for v in values]
Если сигнатура заранее неизвестна, можно использовать
Callable[..., ReturnType], но это стоит делать как крайний
вариант.
## Дженерики (generics)
Generics — это параметризованные обобщённые типы. Проще говоря,
это типы, которые сами принимают типы. Это важно, когда вы хотите
сохранить связь между входом и выходом, а не потерять её в Any.
Например, функция first возвращает элемент того же типа, что и
внутри переданной коллекции:
from collections.abc import Sequence
from typing import TypeVar
T = TypeVar("T")
def first(items: Sequence[T]) -> T:
return items[0]
Без дженериков нам пришлось бы писать Sequence[Any] и терять
тип результата. А с дженериками анализатор знает, что если мы
передали Sequence[str], то вернётся str. Это особенно важно
для коллекций, фабрик и репозиториев, где один и тот же код
обрабатывает разные типы.
Также полезно знать, что у TypeVar есть параметр bound,
который позволяет ограничить те типы, которые могут попадать
в дженерик:
from collections.abc import Hashable, Iterable
from typing import TypeVar
HashableT = TypeVar("HashableT", bound=Hashable)
def mode(data: Iterable[HashableT]) -> HashableT:
...
## Literal
Literal позволяет зафиксировать конкретные допустимые значения,
а не просто базовый тип. Это полезно, когда у параметра есть
закрытый набор режимов, статусов или ключей.
from typing import Literal
def export_report(format: Literal["csv", "json"]) -> bytes:
...
Сигнатура выше сразу задаёт контракт: третьего формата тут нет.
Это делает API понятнее и позволяет анализатору ловить опечатки
вроде "jsno" до запуска.
## Статические анализаторы
И наконец пришло время познакомиться с тем, кто “оживляет” типизацию в Python: со статическими анализаторами. Они читают аннотации, сопоставляют их с кодом и подсвечивают ошибки до runtime.
mypy- классический статический анализатор типов для постепенного внедрения типизации. Сильная сторона: экосистема плагинов и тонкая настройка строгости по модулям. Слабая сторона: без настройки может быть либо слишком мягким, либо слишком шумным.pyright- быстрый и понятный чекер. Сильная сторона: хорошие диагностические сообщения и быстрый feedback. Слабая сторона: расширяемость через плагины хуже, чем вmypy.pyrefly- новый быстрый анализатор на Rust. Сильная сторона: высокая скорость и интеграция с LSP. Слабая сторона: проект ещё молодой, поэтому часть поведения может меняться.ty- новый Rust-инструмент от Astral (пока beta). Сильная сторона: скорость и современная архитектура. Слабая сторона: pre-release стадия, часть возможностей ещё догоняет зрелые чекеры.
Установить и запускать их можно через uv:
uv tool install mypy
uv tool install pyright
uv tool install pyrefly
uv tool install ty
uvx mypy .
uvx pyright .
uvx pyrefly check
uvx ty check
Ниже бизнес-пример с намеренными ошибками типизации:
from dataclasses import dataclass
from typing import NewType
UserId = NewType("UserId", int)
@dataclass
class User:
id: UserId
email: str
is_active: bool
def discount(total: int, percent: int) -> int:
return total - total * (percent / 100)
def send_invoice(user: User, amount: int) -> str:
if not user.is_active:
return None
return f"invoice for {user.email}: {amount}"
def main() -> None:
user = User(id=42, email=123, is_active="yes")
total = discount("1000", 10)
send_invoice(user, "500")
Проверка pyright даст сообщения примерно такого вида:
error: Type "float" is not assignable to return type "int"
error: Type "None" is not assignable to return type "str"
error: "Literal[42]" is not assignable to "UserId"
error: "Literal[123]" is not assignable to "str"
error: "Literal['yes']" is not assignable to "bool"
error: "Literal['1000']" is not assignable to "int"
error: "Literal['500']" is not assignable to "int"
Что важно в этом выводе:
- Ошибки в
discountиsend_invoiceпоказывают нарушение контракта функции: сигнатура обещает одно, реализация делает другое. - Ошибки в
mainпоказывают, что граничный слой (ввод/DTO) передаёт неверные типы в доменную логику. - Сообщение про
UserIdдемонстрирует, зачемNewTypeполезен в бизнес-коде:idпользователя нельзя случайно подменить обычнымintбез явного решения разработчика.
## Stub файлы (.pyi)
Иногда хочется типизировать код, к которому нельзя или неудобно
вносить изменения. Например, это сгенерированный код, код
сторонней библиотеки или даже ваш собственный модуль, где вы не
хотите мешать типы с реализацией. Для этого существуют stub
файлы — файлы с расширением .pyi.
Файл .pyi содержит только типовые сигнатуры и не содержит
реализации. Статические анализаторы ищут их рядом с кодом или в
отдельных пакетах types-*. Пример:
calc.py:
def add(a, b):
return a + b
calc.pyi:
def add(a: int, b: int) -> int: ...
Так вы можете поддерживать типизацию отдельно от реализации, а иногда даже без доступа к исходникам.
## TypeAlias
Когда тип становится сложным, его лучше вынести в алиас, чтобы
сигнатуры были читаемыми. Это особенно полезно для бизнес-терминов
вроде UserId, Currency, Payload. Для этого используют
TypeAlias:
from typing import TypeAlias
UserId: TypeAlias = int
Payload: TypeAlias = dict[str, str | int | float]
Теперь можно писать:
def send(user_id: UserId, payload: Payload) -> None:
...
В Python 3.12+ для того же есть синтаксис type:
type UserId = int
type Payload = dict[str, str | int | float]
Это всё тот же алиас, просто короче и читабельнее.
## TypeAlias vs NewType
TypeAlias — это просто синоним типа, он не создаёт новый тип.
NewType же создаёт новый тип на уровне статической проверки,
хотя на runtime это всего лишь функция-обёртка. Это полезно,
когда у вас есть логически разные значения одного базового типа,
например UserId и OrderId.
from typing import NewType, TypeAlias
UserId: TypeAlias = int
OrderId = NewType("OrderId", int)
def get_user(user_id: UserId) -> None:
...
def get_order(order_id: OrderId) -> None:
...
UserId и int считаются одним и тем же типом, а вот OrderId
уже не совместим с int без явного приведения.
# Как правильно использовать типизацию
Сразу хочу сформировать у вас верную предпосылку относительно типизации. Точно так же как и у тестов, задача у типов падать, не проходить, крашиться и бесить этим нас. Если они этого не делают, их можно просто выкинуть. Это означает, что чем менее снисходительна к нам система типизации, тем лучше для нас. Потому что это заставляет нас думать о том, как писать надёжный и безопасный код. Строгость системы типизации (как и у тестов) помогает выявлять ошибки, но для этого они должны не проходить.
И да, писать действительно корректно типизированный код сложно. Это отдельный навык, который развивается так же, как архитектура или тестирование. Поэтому нормально начинать с малого и постепенно усиливать строгость.
##
Возвращение None
Также обратите внимание на случай, когда функция ничего не возвращает:
def print_weather(weather: Weather):
print("Weather:")
for date, data in weather.by_days().items():
print(date)
print(f"\t{data.temperature}")
print(f"\t{data.humidity}")
print(f"\t{data.wind_speed}")
print("========")
tmp = print_weather(Weather()) + 1
Как известно в Python, если в функции не стоит return, значит
она ничего не возвращает. Об этом знают и статические анализаторы.
Например, pyright для этого кода, где намеренно в последней
строчке допущена ошибка, даст следующее предупреждение:
error:
Operator "+" not supported for types "None" and "Literal[1]"
По этому сообщению становится ясно, что pyright “понимает”, что
возвращаемый тип функции None. Так значит можно их не
подписывать? Нет, не значит. Во-первых, тут можно просто
сослаться на PEP 20, “явное
лучше неявного”. Во-вторых, стоит учесть специфику
developer experience (DX) при разработке на Python. Все, кто пишут на
Python, знают, что типизация опциональна. И это создаёт
двусмысленность: когда я смотрю на сигнатуру функции, где не
специфицировано возвращаемое значение, я не понимаю, это автор
кода просто не стал её типизировать и на самом деле она возвращает
не None, либо там действительно возвращается None.
Разрешается эта двусмысленность только погружением в детали
реализации функции, что усложняет работу с кодом.
## Вход и выход у функции
Продолжим тему возвращаемых значений. Не стоит прибегать
к использованию абстрактных классов из модуля collections.abc,
а также реализованных самостоятельно, для указания возвращаемого
значения из функции. Они предназначены для входных значений,
чтобы сохранить полиморфность функции в максимально широких
границах. Возвращаемое значение должно быть специфицировано
конкретной реализацией, чтобы было ясно, как обрабатывать
возвращаемый результат.
ImportantФункция должна более ясно говорить о том, какой конкретный тип она возвращает, чем принимает.
Если вы хотите углубиться в тему, ниже — отличные материалы, которые помогут настроить инструменты и разобраться в деталях типовой системы Python.
- Типизированный Python для профессиональной разработчики
- FastAPI type hints guide (Полезно для web-разработчиков)
- RealPython, Type Checking Guide
- Упражнения